Introduction
The MLOps adoption has been growing a lot in the last years, we’ve got many of news and research stand out, but other data it’s nearly 90% of machine learning projects fail in some companies themselves never deployed a machine learning model into your environment, another research shows the rise of AI into products and services where companies haven’t much time to do this adoption or jump out of the boat, neglecting your competitive market, this said, I decided to write a post to help “newbies” companies in your first step to implementing MLOps, a guide to the way into a minimal simple, security and scalable architecture.
MLOps Principles
To be a recent term and culture, MLOps has good root principles that are clear to a great part of Big techs and companies with strong maturity in MLOps, why do I say Big techs? because they are the most advanced in MLOps in the industry currently (you should see in references some articles that assert it) the firsts to explore and fail in this discipline, in fact, in most parts of this article you will see tools and practices applied by them, they influence most solutions to goes in the way.
The first principle we’ll see is The Area of MLOps, which is composed of three others tech disciplines already well-known, are Machine learning, DevOps, and Data Engineering. You can see MLOps is an intersection among other disciplines, Machine learning is a core which data to train algorithms to do some specific task, we have DevOps the part concerned to operate the model created in the productions environment which have an automation layer in the process, Data Engineering being part of collected data in several sources, data cleaning, ingestion and finally produce repository with all data cleaned and ready to build an ML model.
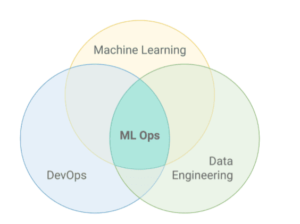
source: Engineering MLOps book
The second principle I’d like to list is DevOps isn’t enough. It’s important to explain the difference between DevOps and MLOps, but, aren’t they the same thing? are they not solving the same problem? the answer is NOT, DevOps came up in software development heyday to solve problem-related Software engineers and infrastructure engineers to deploy systems reliable, to solve this problem in waterfall method back then (check it out here a DevOps history article).
Which is the big difference between them? when we’re doing a machine learning model we have an additional snippet this one is DATA, DevOps was a concept to automate, avoid failure rate for new releases, and improve deployment frequency with regards to only CODE, did you catch the difference? DevOps isn’t aimed to deal with data within or external to code scripts, we have a dual way of concern in a production environment, code, and data.
In DevOps
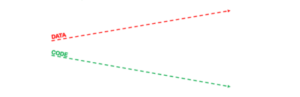
image source: Engineering MLOps book
In MLOps
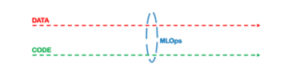
image source: Engineering MLOps book
So then, the MLOps concept was born to solve the dual way between code and data, of course, inherited some DevOps best practices (like automation, CI/CD, units tests monitoring, etc) but with an additional part which is data, in MLOps we’re focused to deliver reliable and scalable ML data-driven systems. besides other particularities that were born in MLOps which we’ll deal in next.
Said that without any further ado let’s jump into ML architecture.
Machine learning Architecture
It’s very similar to software architecture but applied to withstand ML systems, I can’t talk about ML Architecture without quoting a popular article done by the Google Engineering team MLOps: Continuous delivery and automation pipelines in machine learning which presents MLOps architecture in three different levels, inspired by this article I did this architecture based in same, with caveats in pieces of architecture, takes in count my work experience about ML Architecture as well.

source: my design architecture
I did a diagram to show the visual way to easily understand the architecture including the 5 fundamentals blocks in all ML architecture ensuring minimal reliability, scalability, and quick releases. These blocks are composed of Data Ingestion where we can gather data to be used in the model, Model Training indeed train a machine learning model to solve a business problem, Model Registry once the model has been trained we’ve to keep your artifact, Model Evaluation to ensure all metrics have been achieved in this model, Model Serving accounts for deploy a model to be used and by the end, ML Service which is just an illustration of model puts in mobile application, embedded in hardware, anything else more. Let’s jump into details.
Data Ingestion
The first layer to start is about Data Ingestion, said earlier the snippet that changes DevOps to adapt to MLOps is data, a fundamental ingredient in machine learning, real-world we’ve got a Big Data scenario when saying in Data Ingestion, to have a bunch of data available to train a model is enjoyable wherever.
Data comes to a bunch of different sources, relies mainly on your business company what kind of data you’ve got in your hands, sources like databases, CSV files, data from applications, etc. The point is how and where you can keep all this one, not only this layer but all of them is thinking on cloud or newest solutions, turns out be out of the cloud environment and try to do MLOps unreal.

In my experience in the Data ingestion layer usually, use the ETL process to deliver data in good quality to be ready to use for model training, a good tool that it’s very used in data pipelines is Apache Airflow accounts for manager steps to dirty data goes to clean data state, after that with data cleaned we will do ingestion on the data lake, enable access of this data in some repository, in the case on the data lake, we’ve plenty of tools to use as a data lake, I’ll list below some most popular of them and like mentioned earlier focused on cloud tools.
Data Lake tools: AWS S3, AWS Lake Formation, GCP Cloud Storage.



Model Training
It’s much clear what is this step of model training, all machine learning algorithms take data like input to be trained and thus solve a specific task they were trained for, in the last years we’ve seen huge advancements in machine learning algorithms, bigger architectures came up from AI research, so then, we’ve considerably strives in HPC (High-Performance Computing) to support all these new heavy model, because of it the attention point is around infrastructure to endure model training.

Nevertheless, we can train models nowadays in CPU or GPU, depending on the model architecture chosen, matter what will be your machine to run model training, all tools I’ll list below are worth it and support a range of scales that you need.
Besides that, another piece included in model training is a CI/CD concept it’s used in MLOps as well, after training a model before sending it to the model evaluation step, we need to check out some pieces of our code to endure trusty, in the list below will be tools to use for CI/CD.

It’s important to say we’re dealing with a production perspective so that we need to behave like production sense, most people that account for the train a machine learning model, create a model in jupyter notebooks, I’m mean I’m no judge to use jupyter notebooks to train a model, but in production landscape, we’ve to convert this in code script, where we can have more trusty in this one, make sure to be conversant on code scripts rather than notebooks, it’s a good practice.
Model train tools: AWS SageMaker, GCP Vertex AI, Kubeflow, Databricks.
CI/CD tools: GitHub actions, AWS CodeBuild, Jenkins, GCP Cloud Build.






Model Registry
Once the mode has been trained next step before model evaluation is to store a model artifact somewhere, it’s a well-known practice in software engineering regard to storing artifacts produces by code, in ML we need to keep a model artifact to have a tracking record about this model, for example, you’re creating a fraud detection model, fraud is banking market can be cyclic in your behave, probably this model needs be retrained in soon with another behavior in fraud data, comes up the matter to track record model versions, hyperparameters, data was used to and so on.

The model registry enables us to compare past models to new models, performance, and metrics in hand to help Data scientists to back in a loop to create a better model than before, we deliver a good and reliable way to keep info about the model in fast access.
I think (in my experience) the best tool for the model registry we’ve is MLFlow to manage all life cycles of the machine learning model, MLFlow is composed of four key components which are Tracking, Projects, Models, and Registry. Tracking has been accounted for record and query experiments, Projects are focused on code in a format to reproduce on any platform, Models are focused to deploy models in different environments, Registry is to store and manage models in a repository.
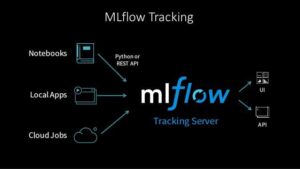
source: MLFlow
Different from other ML architecture layers I focused on say about MLFlow in the model registry layer, of course, we’ve got other solution options out there, which provides great support to your architecture solution.
Model registry tools: MLFlow, AWS SageMaker model registry, Neptune model registry.
Model Evaluation
After the model train and model registry layer we’re interested to Evaluate the model, in several projects that I’ve worked on it’s chosen a target metric in a model to improve as much as possible, some cases were Accuracy, others matter to improve F1 score, and so on, the model evaluation layer is a concern to validate if target metrics has achieved or not, the model is evaluated on a separated set of data points.
Regards tools it’s seems like a model training step, for example, you could use Sagemaker to evaluate metrics, MLFlow to compare metrics through other models, where we need to validate the metrics of the model and if isn’t good enough, we can retrain this model, following the loop again until the model performance has achieved what is expected, usually creating an evaluation environment where you receive different data to test.
Model evaluation tools: AWS SageMaker, MLFlow, Comet.

Model Serving
The last layer is model serving, like mentioned earlier most parts of ML projects failed because they don’t know about think machine learning like software, we’ve seen all parts of the components we’ve got inherent tools and mainly process that is in MLOps as well, model serving is around to deploy a model into production and available to be used by other software or an independent service.
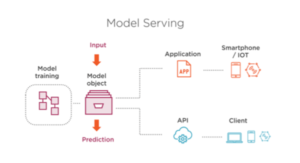
Model serving has to ensure production testing and production releases, is needed to define a standard method to deploy, for example, you can deploy a real-time model delivering an API endpoint you need to define a standard way to put this model in API, or if deploy a batch model is needed to map your output data, things like that needed to be defined in this layer.
Some test we can cover in model serving is API endpoint latency time, how much time API is given a response to application has been consumed, in case to deploy in batch test input and output data once the batch is running verify your stats, the performance and results should be in your expect, tests are crucial before deploying machine learning models.
Model serving tools: AWS SageMaker Endpoints, Kubernetes, FastAPI, TensorFlow Serving, BentoML.




Conclusion
Once your initial ML platform is up we’ve got a follow to improve and generate the most value for the company, the base to get you there is made, there are points to improve to better ML architecture and your services deployed, it’s happening with time and maturity of MLOps team, I’d like to say this architecture was an initial provide by my experience, in the article written by Google (before mentioned) they propose a level 0 architecture which includes nothing about automation, CI/CD, infrequent releases iterations, thus MLOps has grown and nor all is the rule of thumb of, I propose this article in this way one step above to level 0.
What are the next steps? what lack of architecture? Even though we have a base to improve the platform, the next steps involve looking at CT/CM (continuous training and continuous monitoring) concepts whose was born in MLOps, retraining machine learning models are needed, usually data distribution shifts or performance model decrease and comes up the need to retrain a model, CM helps to monitor the health of the model in production.
I hope this article will be useful and clear to you all, the hope is to see more companies doing MLOps on their own, building products and services more reliable which benefit all around it, soon we’ll see great improvements regards tools and good practices, stay tuned to follow the latest releases in MLOps, see you there!.
References
- MLOps Principles: https://ml-ops.org/content/mlops-principles
- Google MLOps: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- Engineering MLOps book: https://virtualmmx.ddns.net/gbooks/EngineeringMLOps.pdf
- Model registry Neptune: https://neptune.ai/blog/ml-model-registry
- MLOps tools Neptune: https://neptune.ai/blog/best-mlops-tools

13 Responses
Hello there! This article could not be written much better! Looking through this post reminds me of my previous roommate! He always kept talking about this. I will forward this article to him. Fairly certain he’ll have a very good read. Thank you for sharing!
Thanks a huge for your feedback Nicki! I’m glad to hear that, stay tuned to the next ones!
HerpaGreens is a novel dietary supplement created to help destroy the herpes simplex virus
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
Hey very cool web site!! Guy .. Excellent .. Superb .. I’ll bookmark your blog and take the feeds additionallyKI am happy to seek out numerous helpful info here in the submit, we want work out extra techniques in this regard, thanks for sharing. . . . . .
I truly prize your work, Great post.
Greetings! I’ve been following your website for a long time now and finally got the courage to go ahead and give you a shout out from New Caney Tx! Just wanted to tell you keep up the good job!
Puravive is a weight management supplement formulated with a blend of eight exotic nutrients and plant-based ingredients aimed at promoting fat burning.
Pretty nice post. I just stumbled upon your weblog and wished to say that I’ve really enjoyed browsing your blog posts. After all I will be subscribing to your rss feed and I hope you write again very soon!
You have brought up a very wonderful points, regards for the post.
There are some fascinating cut-off dates on this article however I don’t know if I see all of them heart to heart. There is some validity but I will take hold opinion till I look into it further. Good article , thanks and we would like extra! Added to FeedBurner as effectively
Wonderful blog! I found it while browsing on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Thank you
Please let me know if you’re looking for a writer for your blog. You have some really great articles and I believe I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some content for your blog in exchange for a link back to mine. Please blast me an e-mail if interested. Regards!