Introduction
The Language models are present in the NLP field starting with probabilistic soft models, language models aim to estimate the probability of different linguistics units like symbols, tokens, token sequences, etc, in summary, LM estimates the probabilities of these events, but in the last few years, we’ve seen a huge born of Large language models in NLP, it’s an indeed breakthrough around language models, thus be able to understand a chat conversation, summarize documents in minutes, generate text like a human person, these are one of the traits of LM can do, let’s deep dive in.
Summary
- What are Language models?
- Probabilistic Language model
- The Age of Large Language models
- Conclusion
- References
What are Language models ?
The Language model is a computer algorithm that can understand and recognize a text by estimating the probability of different linguistic traits, the most simple example of a language model in literature is the probabilistic language model also called the N-Gram model (we’ll see in forwarding section), which is proposed to predict the next word given before word in a text sequence.

To spotlight one application that is using a language model behind the hood of are typing bar in smartphones when anyone typing a message behind this app has a language model running to predict the next word given the sequence of text, it’s more popular called auto-complete typing.
Nowadays with strives for deep learning, we’ve seen new models that are alias to the age of Large language models in which language models are crafted by neural networks rather than probabilistic models, enabling more complex and outperforming applications regards before, with a new spread of applications like text classification, language translation, generative language and so on.
Probabilistic Language models
The first approach made to Statistical Language models was a probabilistic method, which is known for making a probability distribution over word sequences, which assigns a probability to the whole sequence of words.

But we have a problem with this method, which is known as Data sparsity the most possible word can’t be present in the training data, thus the prediction can be wrong because the next word isn’t present in the training data, the solution for this makes a given a word dependent of a previous word in a sequence, for example: “I’m going to travel to Italy” to predict a country that I’m going travel is needed to take into account previous N-words, comes up a method called N-Gram which provides a probability distribution of the words given a sequence.
This is a Relavtive likelihood concept that is useful for many NLP applications speech recognition, machine translation, information retrieval, etc. let’s introduce the n-grams models. let’s say we have tokens y1, y2, y3 which represent words, we have a probability of these tokens as well P(y1, y2, y3, . . . , yn), using a chain rule of probability.
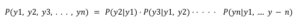
formally in the end, we’ve:

We decomposed the probability of a text into conditional probabilities of each token given the previous context, all we did is conditional probabilities, bellow I did a python code with a function that calculates a word probability within a sequence.
import nltk
nltk.download('punkt')
from nltk import ngrams
from nltk.tokenize import word_tokenize
# sentence example
sentence = "I saw an airplane over and Paris more than one time"
# word probability function
def word_proba(sentence, word):
sentence_tokens = word_tokenize(sentence)
word_count = 0
total_words = 0
for w in sentence_tokens:
total_words += 1
if w==word:
word_count += 1
ngram_proba = (word_count / total_words)
print("This word probability is:", ngram_proba)
# call function ("over" word probabillity)
word_proba(sentence, "over")
# output
This word probability is: 0.09090909090909091
Which to calculate a word probability within a sequence is:

N-Grams
n-gram language models also count global statistics from a text corpus, like we’ve seen so far, the probability of a word only depends on a fixed number of previous words, thus unigram references to use n-words in context to predict the next ones.
for example:
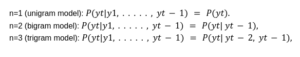
bellow a short python code example of n-gram model:
import nltk
nltk.download('punkt')
from nltk import ngrams
# sentence example
sentence = "I saw an airplane over and Paris more than one time"
# unigram model
uni_ngram = ngrams(sentence.split(), 1)
for gram in uni_ngram:
print(gram)
print("\n\n")
# bigram model
bi_gram = ngrams(sentence.split(), 2)
for gram in bi_gram:
print(gram)
print("\n\n")
# trigram model
tri_gram = ngrams(sentence.split(), 3)
for gram in tri_gram:
print(gram)
# output
('I',)
('saw',)
('an',)
('airplane',)
('over',)
('and',)
('Paris',)
('more',)
('than',)
('one',)
('time',)
('I', 'saw')
('saw', 'an')
('an', 'airplane')
('airplane', 'over')
('over', 'and')
('and', 'Paris')
('Paris', 'more')
('more', 'than')
('than', 'one')
('one', 'time')
('I', 'saw', 'an')
('saw', 'an', 'airplane')
('an', 'airplane', 'over')
('airplane', 'over', 'and')
('over', 'and', 'Paris')
('and', 'Paris', 'more')
('Paris', 'more', 'than')
('more', 'than', 'one')
('than', 'one', 'time')
The Age of Large Language Models
The age of Large Language models began at the beginning of the past decade, which came up with the first large-scale models that solved NLP tasks, the first one we can point out is BERT (Bidirectional Encoder Representations from Transformers) a model which uses a masked language model and some tricks to achieve back then a SOTA (state-of-the-art) results.
Some aspects are being explored by AI researchers like model performance x model size each year we’ve seen a new architecture that overperforms the previous model with a good performance beats the new SOTA current, some alternatives we’ve been tested like Distillation, Pruning, Quantization and so on, the graphic below illustrates the current landscape the trade-off model size and parameters.
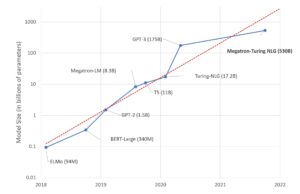
source: https://huggingface.co/blog/large-language-models
This is a problem most research is trying to solve, reduce model parameters size to maintain good relevant performance, the cost to train from scratch large language models is so expensive, Megatron-Turing NLG has 530B of parameters extremely huge model, to train a model like that you’ll need a robust infrastructure with dozens of GPUs to support this training process, roughly $ 100 million dollars cost to build an infrastructure which endures this monster, with this said, we’ll jump to a stand-out some breakthroughs in Large language models in the last few years.
BERT
Bidirectional Encoder Representations from Transformers (BERT) is a transformer-based machine learning technique for natural language processing (NLP) pre-training developed by Google, The original English-language BERT has two models:[1] (1) the BERTBASE: 12 encoders with 12 bidirectional self-attention heads, and (2) the BERTLARGE: 24 encoders with 16 bidirectional self-attention heads. Both models are pre-trained from unlabeled data extracted from the BooksCorpus with 800M words and English Wikipedia with 2,500M words.
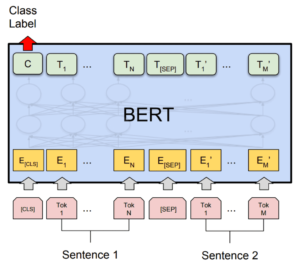
BERT was pre-trained on two tasks: language modeling (15% of tokens were masked and BERT was trained to predict them from context) and next sentence prediction (BERT was trained to predict if a chosen next sentence was probable or not given the first sentence). As a result of the training process, BERT learns contextual embeddings for words. After pretraining, which is computationally expensive, BERT can be finetuned with fewer resources on smaller datasets to optimize its performance on specific tasks.
When BERT was published, it achieved state-of-the-art performance on a number of natural language understanding tasks:
- GLUE (General Language Understanding Evaluation) task set (consisting of 9 tasks)
- SQuAD (Stanford Question Answering Dataset) v1.1 and v2.0
- SWAG (Situations With Adversarial Generations)
T5
The T5 model was presented in Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. T5 means “Text-to-Text Transfer Transformer”: Every task considered — including translation, question answering, and classification — is cast as feeding the T5 model text as input and training it to generate some target text.

A combination of model and data parallelism is used to train models on “slices” of cloud TPU pods, 5 TPUs pods are multi-rack ML supercomputers that contain 1,024 TPU v3 chips connected via a high-speed 2D mesh interconnected with supporting CPU host machines.
The most obvious new idea behind this work is that it is a text-to-textmodel: During training, the model is asked to produce new text as an output, even for training tasks that would normally be modeled as classification and regression tasks with much simpler kinds of output. However, this idea seems to have been chosen out of engineering convenience, and there’s no evidence that it’s necessary for the results they’ve seen.
GPT-3
Generative Pre-Training Transformer 3 ( GPT-3 ) is an autoregressive language model that uses deep learning to produce human-like text. It is the third-generation language prediction model of the GPT-n series (and the successor to the GPT-2 ) created by OpenAI , a San Francisco-based artificial intelligence research lab.
The full version of GPT-3 is capable of 175 billion machine learning parameters. Introduced in May 2020 and in beta testing in July 2020, this version is part of a trend in natural language processing (NLP) systems of pre-trained language representations.

The quality of text generated by GPT-3 is so high that it is difficult to distinguish it from that written by a human, which has benefits and risks. Thirty-one researchers and engineers from OpenAI presented the original paper on May 28, 2020 introducing GPT-3.
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks.
In practice, GPT-3 can be used in different applications and there are already several cases in which the tool was applied precisely to test its potential. An example of a task that the program is capable of fulfilling is rewriting texts that were written with a rough tone to make them more user-friendly.
Another case is creating custom layouts: just describe the type of layout you want and the program will return the code. There is also the possibility of applying the GPT-3 with chatbots — after all, with the model’s predictive capacity, it is likely that its application will facilitate the creation of virtual assistants that better simulate human interaction!
Conclusion
Language models have been growing and generating impact in our society, we’ve seen throughout this post the huge strides NLP in front language models, a perspective of researchers trying to reduce model sizes likewise ensure amazing metrics performance, the evolution of NLP goes by to Large language models in specific like GPT-3 breakthrough comes to create models like Generalist tasks.
Moving forward LLM we’ll be excited about the new advancements are comes out soon, another perspective is regarded NLP community which has been a much collaborative with staff around the world and is willing to do research, I’ve seen startups and companies like HuggingFace, AssemblyAI and EleutherAI are examples of open-source research labs, awesome to see the evolution of NLP goes by different cultures and point of view, stay tuned what’s to come!
References
[1] Language Modeling course by Lena voita
[3] Large language models by HuggingFace
[4] Language model survey by Synced
[5] How language models will transform science by Stanford

74 Responses
Thanks for your blog, nice to read. Do not stop.
Thank you, Mark! I took a vacation but now I’m back, stay tuned to new posts!
I truly prize your piece of work, Great post.
My spouse and i have been very contented when John could finish up his studies using the precious recommendations he grabbed from your weblog. It’s not at all simplistic just to find yourself making a gift of information and facts which often people may have been trying to sell. And we also grasp we’ve got the blog owner to thank because of that. The entire illustrations you made, the easy website navigation, the friendships you will help engender – it’s many overwhelming, and it is making our son and our family know that that concept is amusing, which is certainly particularly fundamental. Many thanks for the whole lot!
I think that is one of the such a lot vital information for me. And i’m happy studying your article. But want to observation on some normal things, The site style is ideal, the articles is in reality nice : D. Just right activity, cheers
Magnificent website. Plenty of useful information here. I am sending it to some pals ans also sharing in delicious. And obviously, thanks for your sweat!
Awsome website! I am loving it!! Will come back again. I am taking your feeds also
Java Burn: What is it? Java Burn is marketed as a natural weight loss product that can increase the speed and efficiency of a person’s natural metabolism, thereby supporting their weight loss efforts
As soon as I detected this web site I went on reddit to share some of the love with them.
Woah! I’m really enjoying the template/theme of this blog. It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between user friendliness and visual appearance. I must say that you’ve done a amazing job with this. Also, the blog loads very quick for me on Chrome. Outstanding Blog!
This is very fascinating, You are a very professional blogger. I’ve joined your rss feed and stay up for in search of extra of your wonderful post. Additionally, I have shared your website in my social networks!
Some truly interesting info , well written and broadly speaking user genial.
Utterly written written content, Really enjoyed reading.
Thank you for some other informative web site. The place else may I get that kind of information written in such an ideal manner? I’ve a undertaking that I am simply now working on, and I’ve been on the look out for such info.
Undeniably believe that that you said. Your favourite justification appeared to be on the net the easiest thing to have in mind of. I say to you, I certainly get annoyed while folks think about issues that they just don’t recognize about. You controlled to hit the nail upon the top and defined out the entire thing with no need side-effects , other folks can take a signal. Will probably be back to get more. Thanks
Appreciate it for this marvellous post, I am glad I found this website on yahoo.
Perfectly indited subject material, Really enjoyed reading.
A person essentially help to make seriously articles I would state. This is the first time I frequented your web page and thus far? I surprised with the research you made to create this particular publish amazing. Wonderful job!
Have you ever thought about including a little bit more than just your articles? I mean, what you say is valuable and all. Nevertheless just imagine if you added some great graphics or video clips to give your posts more, “pop”! Your content is excellent but with images and video clips, this site could certainly be one of the best in its field. Fantastic blog!
What Is Sumatra Slim Belly Tonic? Sumatra Slim Belly Tonic is a natural formula that supports healthy weight loss.
Way cool, some valid points! I appreciate you making this article available, the rest of the site is also high quality. Have a fun.
WONDERFUL Post.thanks for share..more wait .. …
I think other web-site proprietors should take this website as an model, very clean and fantastic user friendly style and design, let alone the content. You are an expert in this topic!
Your home is valueble for me. Thanks!…
I conceive you have mentioned some very interesting details, appreciate it for the post.
Hey are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you require any html coding knowledge to make your own blog? Any help would be really appreciated!
I must convey my affection for your kindness giving support to persons that must have help with the theme. Your real dedication to getting the solution all through had been remarkably interesting and have truly helped folks like me to arrive at their ambitions. Your amazing useful recommendations entails much to me and substantially more to my office workers. Many thanks; from all of us.
I don’t even know the way I finished up here, but I believed this publish was once great. I don’t recognise who you are but definitely you are going to a famous blogger when you aren’t already 😉 Cheers!
I really appreciate your work, Great post.
I really enjoy looking through on this internet site, it holds superb content.
What Is Puravive? Puravive is an herbal weight loss supplement that supports healthy weight loss in individuals.
You actually make it seem so easy with your presentation however I to find this topic to be really something that I believe I would never understand. It kind of feels too complex and very huge for me. I am taking a look forward in your next post, I’ll attempt to get the hold of it!
I appreciate, cause I found exactly what I was looking for. You have ended my 4 day lengthy hunt! God Bless you man. Have a nice day. Bye
Absolutely written articles, Really enjoyed examining.
This website online is mostly a walk-by way of for all of the information you wanted about this and didn’t know who to ask. Glimpse right here, and also you’ll positively uncover it.
I’m really impressed with your writing skills as well as with the layout on your weblog. Is this a paid theme or did you modify it yourself? Anyway keep up the excellent quality writing, it is rare to see a great blog like this one nowadays..
With havin so much content do you ever run into any issues of plagorism or copyright violation? My blog has a lot of exclusive content I’ve either written myself or outsourced but it looks like a lot of it is popping it up all over the internet without my authorization. Do you know any solutions to help reduce content from being ripped off? I’d certainly appreciate it.
I was reading through some of your content on this website and I conceive this site is very instructive! Retain putting up.
It’s hard to search out knowledgeable individuals on this topic, however you sound like you know what you’re speaking about! Thanks
Lottery Defeater Software: What is it? Lottery Defeater Software is a completely automated plug-and-play lottery-winning software. The Lottery Defeater software was developed by Kenneth.
fantastic points altogether, you just gained a new reader. What would you suggest about your post that you made a few days ago? Any positive?
Great V I should certainly pronounce, impressed with your web site. I had no trouble navigating through all tabs and related information ended up being truly simple to do to access. I recently found what I hoped for before you know it in the least. Quite unusual. Is likely to appreciate it for those who add forums or something, website theme . a tones way for your customer to communicate. Excellent task..
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100 certain. Any suggestions or advice would be greatly appreciated. Thank you
Hi, I think your site might be having browser compatibility issues. When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, fantastic blog!
Hi there, I discovered your site by means of Google at the same time as looking for a related subject, your web site came up, it appears great. I’ve bookmarked it in my google bookmarks.
hello there and thanks to your information – I have definitely picked up something new from proper here. I did on the other hand expertise some technical points the use of this website, as I experienced to reload the website many occasions prior to I may just get it to load properly. I were thinking about in case your hosting is OK? Now not that I am complaining, however slow loading instances instances will very frequently have an effect on your placement in google and can injury your quality ranking if ads and ***********|advertising|advertising|advertising and *********** with Adwords. Anyway I am adding this RSS to my email and could glance out for a lot more of your respective interesting content. Ensure that you update this once more soon..
Hey, you used to write excellent, but the last several posts have been kinda boringK I miss your super writings. Past several posts are just a little bit out of track! come on!
I’m not sure where you’re getting your information, but great topic. I needs to spend some time learning more or understanding more. Thanks for excellent information I was looking for this info for my mission.
Hmm is anyone else encountering problems with the images on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
I was just searching for this info for a while. After 6 hours of continuous Googleing, finally I got it in your website. I wonder what’s the lack of Google strategy that don’t rank this type of informative web sites in top of the list. Usually the top websites are full of garbage.
Nice read, I just passed this onto a friend who was doing a little research on that. And he just bought me lunch since I found it for him smile So let me rephrase that: Thanks for lunch!
With havin so much content and articles do you ever run into any issues of plagorism or copyright infringement? My website has a lot of exclusive content I’ve either written myself or outsourced but it appears a lot of it is popping it up all over the web without my authorization. Do you know any solutions to help prevent content from being ripped off? I’d definitely appreciate it.
I really appreciate this post. I¦ve been looking all over for this! Thank goodness I found it on Bing. You’ve made my day! Thank you again
I’m really enjoying the design and layout of your website. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme? Exceptional work!
I’ve been exploring for a little for any high-quality articles or weblog posts in this kind of house . Exploring in Yahoo I at last stumbled upon this web site. Studying this info So i’m happy to show that I have an incredibly good uncanny feeling I found out exactly what I needed. I such a lot unquestionably will make sure to do not disregard this site and give it a glance on a relentless basis.
Good day! Do you use Twitter? I’d like to follow you if that would be okay. I’m absolutely enjoying your blog and look forward to new updates.
It’s appropriate time to make some plans for the future and it is time to be happy. I’ve learn this publish and if I may I want to counsel you some fascinating things or advice. Maybe you can write next articles regarding this article. I want to read more issues about it!
The following time I read a blog, I hope that it doesnt disappoint me as much as this one. I mean, I do know it was my choice to learn, but I really thought youd have something attention-grabbing to say. All I hear is a bunch of whining about something that you could fix when you werent too busy searching for attention.
Lovely just what I was searching for.Thanks to the author for taking his clock time on this one.
Howdy are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you require any coding knowledge to make your own blog? Any help would be really appreciated!
I loved as much as you’ll receive performed proper here. The cartoon is tasteful, your authored material stylish. nonetheless, you command get got an impatience over that you would like be turning in the following. in poor health without a doubt come further formerly again as precisely the same nearly very incessantly inside case you shield this hike.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to more added agreeable from you! By the way, how could we communicate?
Its like you read my thoughts! You seem to grasp a lot about this, such as you wrote the book in it or something. I think that you just could do with some to force the message home a little bit, however other than that, this is magnificent blog. A fantastic read. I’ll certainly be back.
I’m still learning from you, but I’m trying to achieve my goals. I certainly love reading all that is written on your site.Keep the stories coming. I loved it!
I keep listening to the newscast speak about receiving free online grant applications so I have been looking around for the best site to get one. Could you tell me please, where could i get some?
Hello there, You have done an incredible job. I will certainly digg it and personally recommend to my friends. I am confident they’ll be benefited from this web site.
I really like your writing style, good info, appreciate it for posting :D. “Freedom is the emancipation from the arbitrary rule of other men.” by Mortimer Adler.
Very interesting information!Perfect just what I was searching for!
My spouse and i have been absolutely relieved when Jordan managed to conclude his investigations using the ideas he had in your blog. It is now and again perplexing just to find yourself giving for free guidance that a number of people might have been making money from. So we understand we have got the website owner to thank for this. These explanations you made, the easy web site navigation, the friendships your site help to instill – it is many fantastic, and it is letting our son and us feel that that subject matter is interesting, and that is tremendously essential. Many thanks for all!
Great post. I was checking constantly this blog and I’m impressed! Very helpful information particularly the last part 🙂 I care for such info much. I was looking for this certain info for a long time. Thank you and good luck.
https://cr-v.su/forums/index.php?autocom=gallery&req=si&img=4027
Hey! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me. Anyhow, I’m definitely glad I found it and I’ll be book-marking and checking back often!
Привет любителям экспериментов!
Надёжный советник для всех — ChatGPT. Создавайте контент, находите выход из ситуаций или повышайте свою квалификацию. Ответы всегда точные и понятные. Для медиа-специалистов — привлекательные посты, для преподавателей — планы уроков. В Telegram он помогает вести дела. Попробуйте сами — результат гарантирован!
Открыть сайт: https://yarchatgpt.ru
джитипи
Не ждите идеального момента — создайте его!
What you’ve written here is not just a collection of ideas — it’s a conversation, one that spans across time and place. Your words evoke such a rich tapestry of images and emotions that it’s impossible not to be swept up in them. There’s an intimacy to the writing, a quiet understanding that connects the reader to something much larger than themselves.